

언론사가 개발한 첫번째 거대언어모델(LLM), 블룸버그GPT. 이것의 등장은 사실 충격에 가까웠습니다. '언론사도 거대언어모델 경쟁에 뛰어들 수 있는 건가?'라는 희망의 메시지를 던진 셈이어서입니다. 자체 모델 개발을 위해서는 막대한 비용과 학습 데이터가 필요하기에 언론사들은 기 구축된 언어모델을 변형, 응용 하는 수준에서 도입 검토를 해온 것이 사실입니다. 하지만 블룸버그GPT의 등장은 언론사들도 이 경쟁에서 의미있는 위치를 확보할 수 있다는 자신감을 불어넣었습니다. 당연히 국내 일부 언론사들도 관심을 보이기도 했고요.
블룸버그GPT처럼 자체 거대언어모델을 가지려면 어떤 조건이 필요한지를 살펴보면서, 국내 언론사의 시도 가능성을 한번 점쳐 보겠습니다.
어떤 모델에서 시작했나 : BLOOM



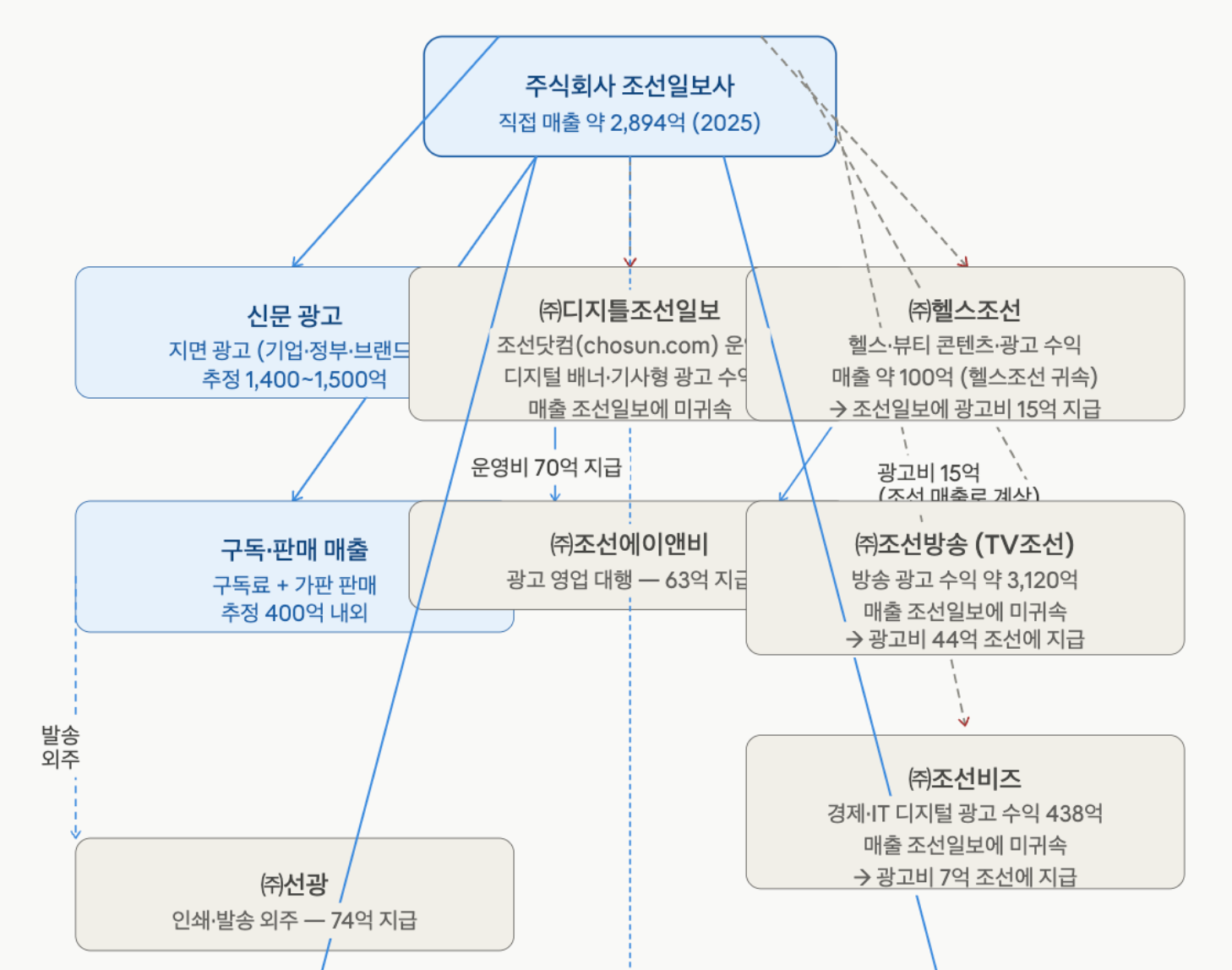
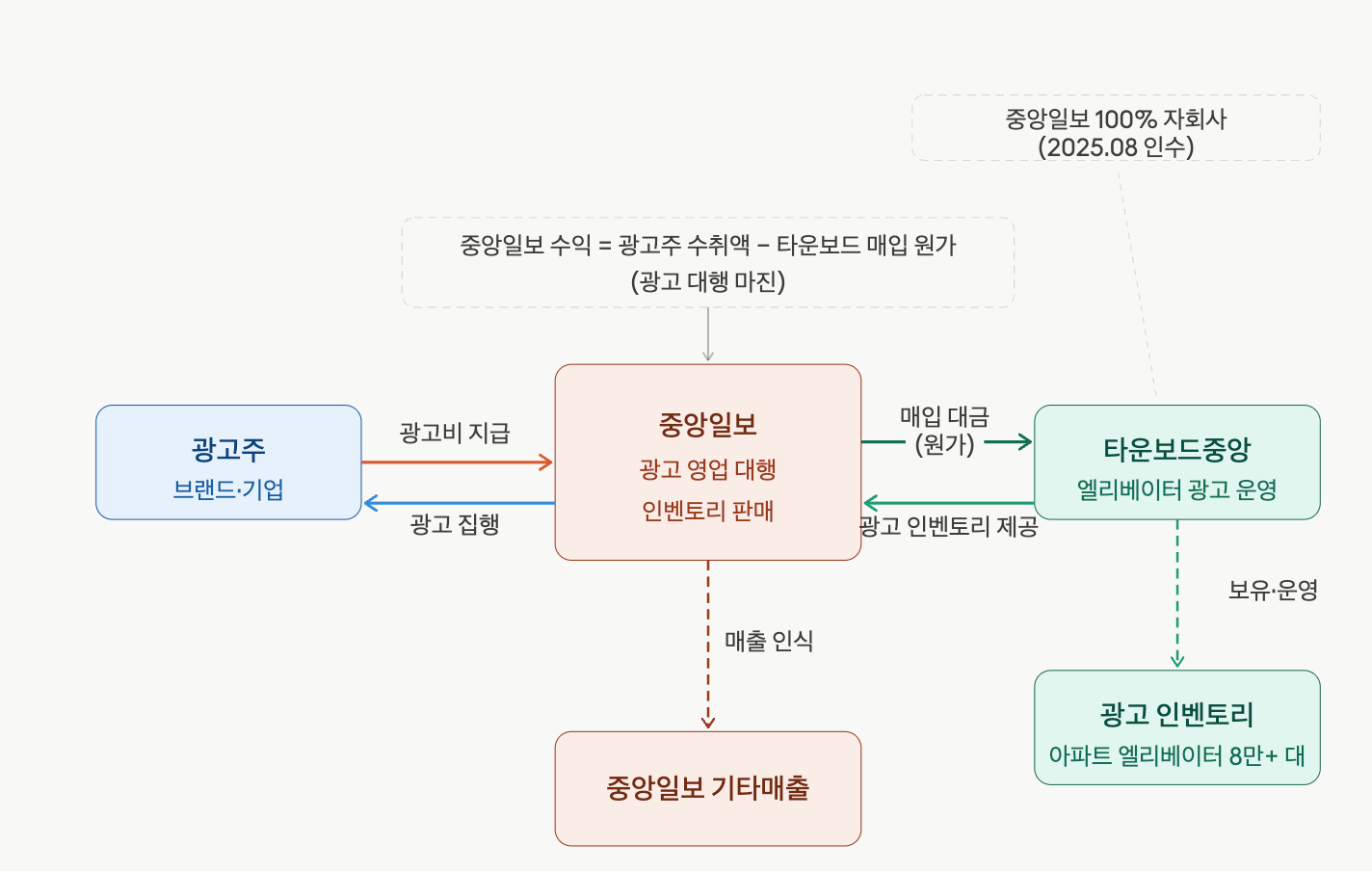

![[발표자료] AI검색 환경 변화와 GEO - PR의 역할](https://cdn.media.bluedot.so/bluedot.thecore/2026/05/n946c0_202605220559._Layout_Visuals_Use_a_stylish_and_highcontrast_color_palette_such_as_a_dark_charcoal_background_with_vibr.png)


![[자료] '제로 클릭' AI 검색이 뉴스 비즈니스에 미치는 영향과 대안](https://cdn.media.bluedot.so/bluedot.thecore/2025/11/ivacbx_202511130202.png)
![[발표자료] GEO시대, 미디어채널 재설계 전략
- AI가 답하는 세상, 당신의 브랜드는 준비되었나요?](https://cdn.media.bluedot.so/bluedot.thecore/2025/09/povk3t_202509261048.jpg)
![[자료] AI 시대, 해외언론사들의 AI 도입 현황과 전략](https://cdn.media.bluedot.so/bluedot.thecore/2025/09/aqzesl_202509220109.10.png)
![[자료] AI 기반의 팩트체킹 방법론](https://cdn.media.bluedot.so/bluedot.thecore/2025/09/ebjijm_202509220114.18.png)

