Google Zero 시대, 혁신의 파도
“세상이 가장 사랑하는 계절은 봄이다. 5월엔 모든 것이 가능해 보인다.” ― 에드윈 웨이 틸(Edwin Way Teale)1966년 퓰리처상을 수상한 에드윈 웨이 틸은 (사진)작가로서 자연을 탐사하는데 일생을 보냈습니다. 그에게 5월의 자연은 언제나 새로움을 불러오는 시기입니다. 2025년 5월 우리는 인류를 바꿀 새로운 기술 시대의 서막 앞에 서 있습니다. 어쩌면 새로운 기술


“세상이 가장 사랑하는 계절은 봄이다. 5월엔 모든 것이 가능해 보인다.” ― 에드윈 웨이 틸(Edwin Way Teale)1966년 퓰리처상을 수상한 에드윈 웨이 틸은 (사진)작가로서 자연을 탐사하는데 일생을 보냈습니다. 그에게 5월의 자연은 언제나 새로움을 불러오는 시기입니다. 2025년 5월 우리는 인류를 바꿀 새로운 기술 시대의 서막 앞에 서 있습니다. 어쩌면 새로운 기술
화웨이, SMIC 등 중국 기업들은 미국의 강력한 제재에도 불구하고 반도체 개발에서 괄목할만한 진전을 보이고 있습니다. 중국이 보여주고 있는 AI 칩 생산 능력의 발전은 ‘중국에 대한 기술 고립 정책’의 한계를 보여주고 있습니다. 2022년 10월 미국 바이든 행정부는 중국의 첨단 반도체 및 슈퍼컴퓨터 기술 개발을 억제하기 위해 포괄적인 수출 통제 조치를

인간은 자신을 표현하고 싶어하고, 이해받고 싶어하며, 연결되어 있음을 느끼고 싶어합니다. 인간은 외롭지 않고 싶어하는 욕구가 있습니다. 이 열망과 욕구는 지난 20년간 페이스북, 인스타그램, 유튜브, 틱톡 등 소셜 미디어 플랫폼이 성장할 수 있었던 출발점이었습니다. 인간 상호작용은 우리의 선택지가 아닙니다. 인간 상호작용은 인간 삶에 반드시 필요한 구성 요소입니다. (유선 및 무선) 인터넷

AI의 기억력 또는 메모리는 AI 에이전트보다 더 전략적으로 중요한 주제이며, AI의 다른 어떤 것보다도 중요합니다. 이는 앞으로 더욱 강력해질 것입니다. 이러한 변화와 그 의미를 자세히 살펴보겠습니다. 먼저 지난 4월 11일 샘 올트만의 이야기를 들어보겠습니다. 우리는 chatgpt의 메모리를 크게 개선했습니다. 이제 모든 과거 대화를 참조할 수 있습니다! 이것은 놀랍도록 훌륭한 기능이며,
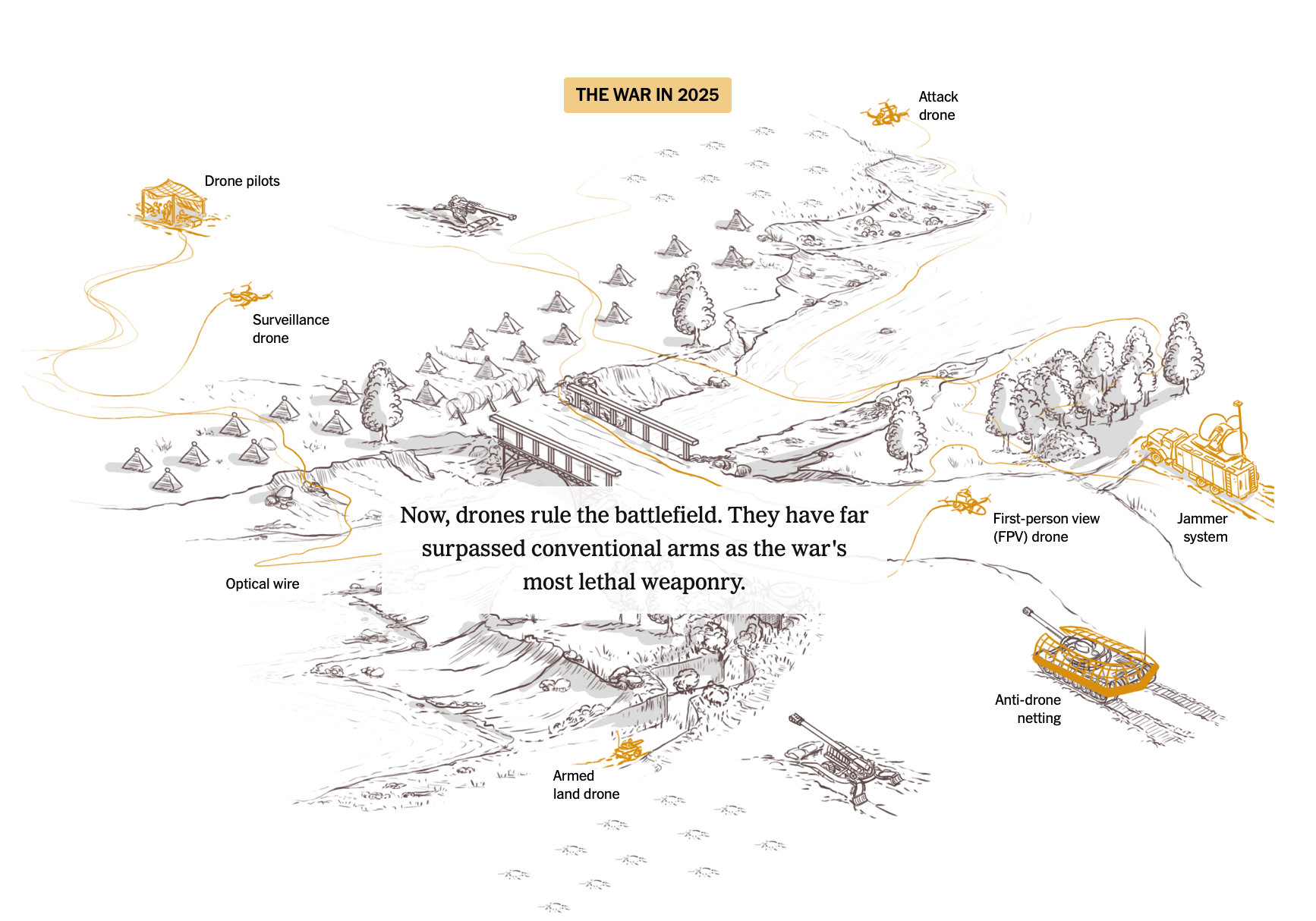
한국군은 과거 전쟁 개념을 벗어나 미래 전쟁에 맞는 새로운 국방 전략을 필요로 합니다. 우크라이나 전쟁은 2,500만 달러 탱크를 5,000달러짜리 드론이 어떻게 파괴할 수 있는지를 보여주고 있습니다. 미래의 전쟁은 AI로 제어되는 네트워크 드론을 기반으로 하는 자율 무기 시스템에 달려 있습니다. 한반도 전쟁 억지력에 대한 신뢰도를 높이기 위해선 로봇과 무인
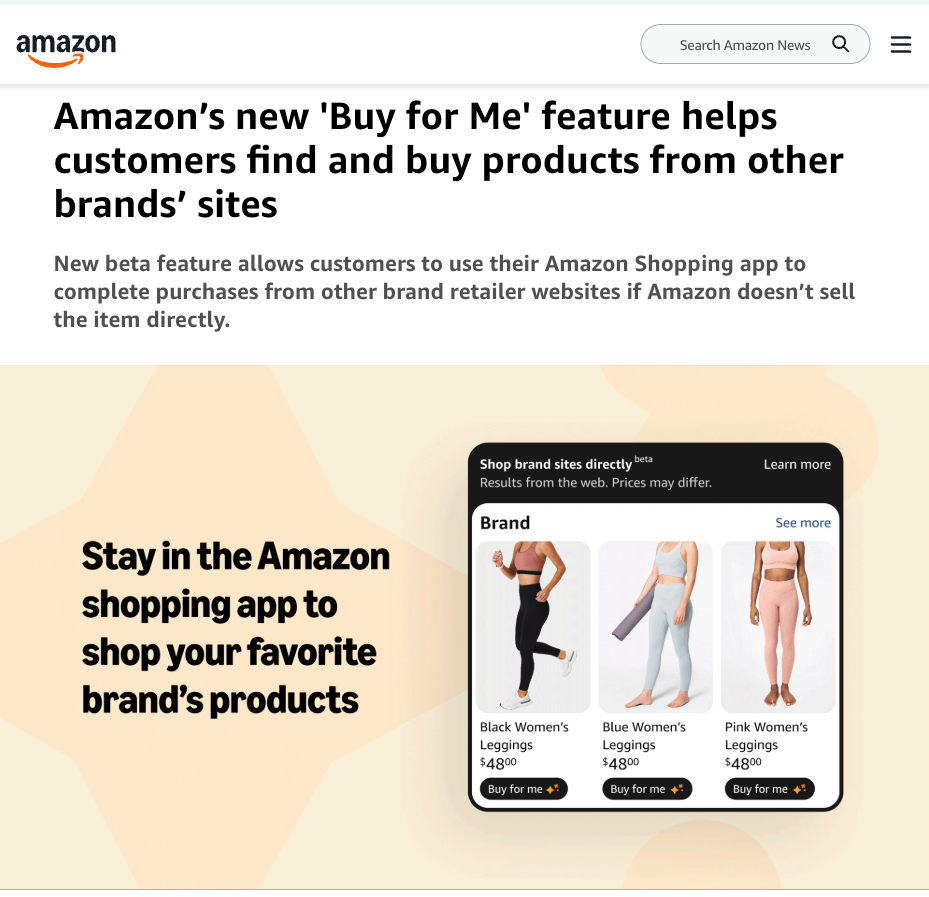
만약 쿠팡이 쇼핑 에이전트를 제공한다면, 여러분은 쿠팡에 머물면서 네이버 스토어와 테무에서 쇼핑을 할 수 있습니다. 아마존이 테스트하고 있는 쇼핑 에이전트 Buy for me는 이커머스에서 게임의 규칙을 재정의할 수 있습니다. Buy for me를 통해 아마존 이용자는 아마존을 떠나지 않고도 아마존을 통해 타사 웹사이트/앱에서 상품을 구매할 수 있습니다. Buy for me는
글을 시작하기에 앞서 첫 번째로 2025년 3월 20일 공개된 벤 톰슨과 샘 올트만(Sam Altman)의 인터뷰를 추천합니다. 이 인터뷰는 샘 알트만의 성장 배경과 OpenAI의 탄생, OpenAI 및 GPT/ChatGPT의 진화, OpenAI는 소비자 기술 기업인가?, 비즈니스 모델 및 광고, 경쟁 및 오픈소스에 대한 입장, AI의 미래와 AGI, 기술 전망과 철학,

제가 글을 즐겨 쓰는 이유를 묻는다면 질투심때문입니다. 너무나 뛰어난 분석 능력을 가진 사람의 글을 읽을 때면 존경심 반, 질투심 반이 제게 생겨납니다. 그들이 쓴 글을 꼼꼼하게 챙겨 읽으며 그리고 그들이 읽은 글을 따라 읽으며 흉내를 내보곤 합니다. 턱없이 모자란 제 능력을 깨닫는데는 오래 걸리지 않습니다. 쫓아가는 것을 포기하고 배우려는 마음만으로

The Core는 2025년 1월 6일 “AI 브라우저, 웹과 앱의 새로운 권력 투쟁”에서 브라우저와 AI 에이전트 기술이 결합하면서 AI가 인간과 똑같은 방식으로 브라우저를 조작할 수 있는 수준으로 기술이 발전하고 있다고 분석했습니다. AI 브라우저 시장에 오픈AI, 구글, 엔트로픽, 마이크로소프트, 애플 등이 뛰어들었습니다. AI 브라우저에 AI 검색, 딥 리서치, 쇼핑 에이전트 등

2025년 우리는 마침내 21세기를 시작하고 있습니다. 미국 4개 빅테크 기업은 2025년 3,000억 달러 이상을 AI에 투자하려고 합니다. 새로운 칩은 AI 추론(inference)에 혁명을 일으키고 있습니다. 구글과 메타도 엔비디아에 이어 휴머노이드 로봇 사업 진출을 알리고 있습니다. 태양광은 미래의 지배적 동력원이 될 것입니다. 지금까지 기준으로 여겨왔던 많은 틀과 프레임을 무너뜨리는

딥시크에 대한 엄청난 양의 소음(noise)가 발생하고 있습니다. 이 소음으로 딥시크가 가지고 있는 두 가지 의미(signal)가 덮여지고 있습니다. 이 글은 딥시크의 두 가지 매우 중요한 신호를 정리한 글입니다. R1은 10분의 1 사용 비용과 오픈소스 모델로 OpenAI o1 수준에 도달했습니다. R1이 왜 중요한지, 무엇이 특별한지 그리고 AI 경제

우리는 비로소 AI 경제의 본격적인 시작을 목격하고 있습니다. 누가 승자가 될 수 있을까요? 딥시크(DeepSeek)는 스스로 진화하는 AI 모델을 비용 효율적으로 인류 누구나 사용할 수 있는 길을 열었습니다. AI 경제의 승자는 AI 가속화 소용돌이에 먼저 뛰어드는 기업과 사람이 될 것입니다. 이 글에서는 딥시크(DeepSeek)가 가지고 있는 기술적 그리고
